4月22日、OpenAIは新しい画像生成モデルである「ChatGPT Images 2.0」を発表し、提供を開始した。
本モデルは詳細な指示への追従や正確なオブジェクト配置にくわえ、高密度なテキストのレンダリング性能が向上している。
Introducing ChatGPT Images 2.0
— OpenAI (@OpenAI) April 21, 2026
A state-of-the-art image model that can take on complex visual tasks and produce precise, immediately usable visuals, with sharper editing, richer layouts, and thinking-level intelligence.
Video made with ChatGPT Images pic.twitter.com/3aWfXakrcR
「ChatGPT Images 2.0」は、同社の画像モデルとして初めて思考能力を備えており、ウェブ検索を通じたリアルタイム情報の取得や自己チェックが可能だ。
1つのプロンプトから一貫性のある複数の画像を生成することもでき、マンガのページやポスターの複数のバリエーションの制作などに対応している。
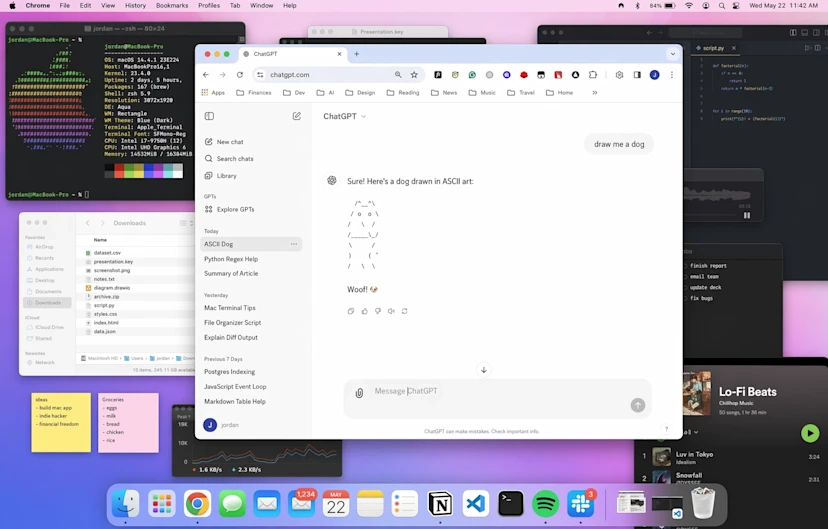
公式サイトでは、多様な生成例とプロンプトが紹介されている。たとえば、「ブラウザ上のChatGPTでアスキーアートの犬を描かせる様子」といったUI画面や、「鉛筆で書かれた野球の歴史に関する手書きのエッセイ」を写真のように生成した例が挙げられている。


本モデルでは、日本語や韓国語といった非ラテン文字を自然に描画する機能も向上しており、「魔法の羽ペンを見つけるシーンを描いた、日本語のマンガのカラーページ」や、「タイポグラフィに関する多言語ポスター」などの例で、その実力が確認できる。

そのほか、“曇りの日の海岸”や“夜の街角にいる友人”といった、不完全さや粒状感まで再現したリアルなスナップショットも公開されている。
本モデルはすべてのChatGPTおよびCodexユーザーが利用できるが、思考能力を用いた高度な出力機能は有料の「Plus」「Pro」および「Business」ユーザーに限定して提供される。
API経由では“gpt-image-2”として公開されており、開発中の製品に画像生成や編集機能を組み込むことも可能だ。