持ち場(テリトリー)を与えられていた初期のゲームAI
ゲーム開発の最初には、そのゲームの中で、どの部分までを人工知能に担当してもらうか、どこを人間がセットアップするかを決めます。人間がプリセットする行動命令(スクリプトと言います)を書いて、どこまでを人工知能の自律的意思に任すかを決めます。
たとえば、1980年代のファミリーコンピュータ(ファミコン)の頃のゲームを思い出してみましょう。ファミコンのゲームのキャラクターたちは自分の持ち場(テリトリー)が決まっていて、キャラクターが現れると一定のパターンの攻撃をくり返します。これは、お掃除ロボットを動かすために空間を空けておく、のと同様です。
ゲームのキャラクターは常に明確な役割を持ちます。プレイヤーにダメージを与えるとか、プレイヤーを足止めしたあとにやられてアイテムを落とすといったことです。それらのキャラクターは、マップのエリアごとに設定され、さらにその中の各キャラクターは持ち場(テリトリー)が与えられ、与えられた役割をこなし、ゲーム全体を繋いでいくのです。つまり「局所的に限定された人工知能」をつないで「全体の人工知能」を作っていると言えます。また、そういった局所を「キャラクターの縄張り(テリトリー)」と解釈してうまくゲームデザインと整合性をつけていたのです。

ボードゲームの盤面認識とルールに則した「思考エンジンとしてのAI」(キャラクターAI)
囲碁、将棋はどうでしょうか。こちらの人工知能はデジタルゲームのような敵キャラクターの人工知能ではなく、相手プレイヤーの役割をする人工知能ですが、一個の盤面をひたすら深く探索します。碁盤はとても広いので、碁のAIは、必ずしも盤面全体を考慮しているのではなく、局所的な形を見て打っています。ですから、局所的な思考を繋いでいるとも言えます。しかし、碁の上級者であるほど、より広い局面を見ながら打つようになります。つまり局所を見ながらも大局を考えながら、さらに局所を打つ、というマルチスケールの間を行き来しながら思考する、複雑系の思考が必要とされます。将棋も同様に局所的な形を見て指す場合もありますが、盤面全体が狭いために、多くは盤面全体を考慮した手になっています。
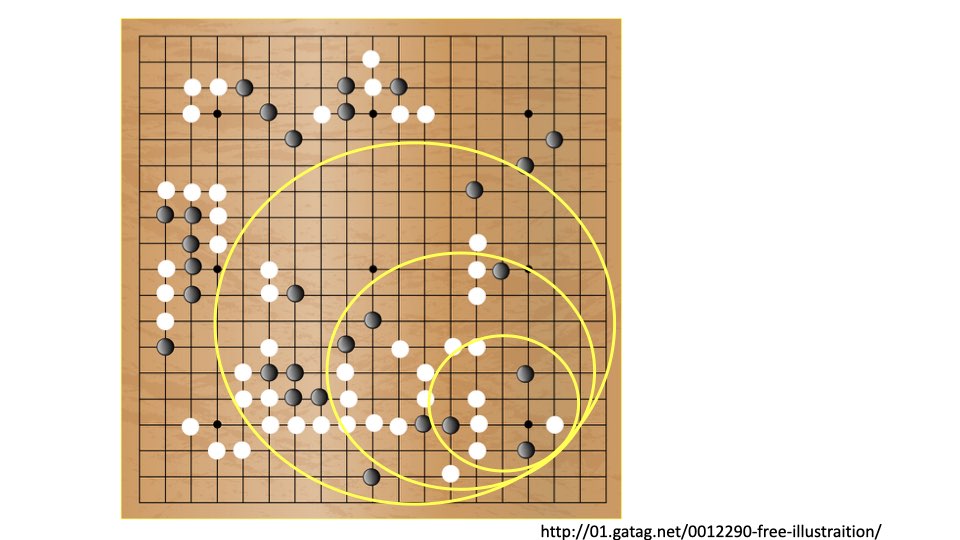
アルファ碁をはじめとするディープラーニングを用いた碁AIが強いのは、前述した「畳み込みニューラルネットワーク」が入っているからで、このニューラルネットワークはマルチスケールに盤面を解析する力があります。
最初は2×2、次に4×4、8×8、のように、段階的にスケールを上げながら解析して各スケールに応じた特徴を抽出します。つまり、局所からだんだん大局に向かっていくマルチスケールな局面解析が可能なのです。そのせいもあって、学習に計算量(時間)がかかりますが、棋譜データが多ければ多いほど、深く局面を学習できます。実際、アルファ碁から次の「Master」は、何千万という盤面データを学習し、盤面を直感的に捉えられるような知能を獲得しています。
このように、与えられたルールに則して人間とプレイヤーと同じ立場で、局面に応じてプレイの中身を自律的に判断する思考エンジンとしての役割が、現代のゲームAIには与えられています。こうした意思決定を担うタイプの人工知能を、「キャラクターAI」と区分することができるでしょう。
ゲームフィールドと環境を統べる「仕組みとしての人工知能」(メタAI)
一方で、将棋や碁のようなターン制の相互手番型ゲームの延長線上に、デジタルゲームではさまざまなフィールドが築かれています。一番印象的なのが『シムシティ』など都市の育成をテーマにした、リアルタイム型のシミュレーションゲームでしょう。『シムシティ』は、ユーザーが工場や発電所、消防署、警察署といったインフラを整備していくと、自然に街が発展していくゲームです。

こうしたフィールドの生成発展を担うのが「仕組みとしての人工知能」ないし「メタAI」で、ユーザーのアクションに応じて自動的に街を発展させていきます。
この自動生成は、次のような仕組みで行われています。まず、『シムシティ』の街のマップは全体がグリッド状のマス目で細かく分割されており、ユーザーはそのどこかのマス目に対し、建物を建設したり道路を敷設したりといったアクションを行います。
すると、入力を受け取ったAIは、ユーザーのコマンドに応じた処理結果をそのマス目に出現させるとともに、そこで起こった事柄を周囲のマス目に波及させていきます。
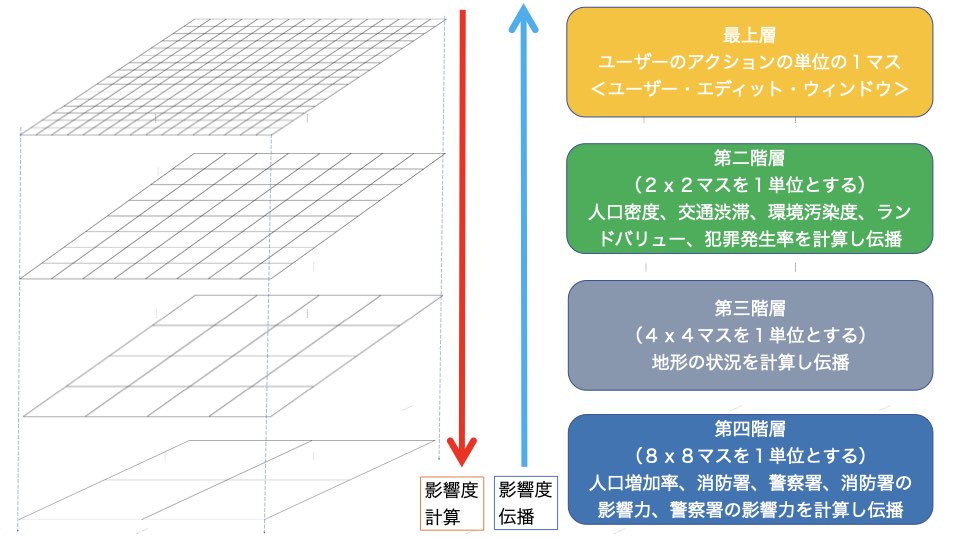
このときにAIが処理する影響の範囲が、ミクロなスケールからマクロなスケールまで階層的に設定されているのが、『シムシティ』の特徴です。つまり、ユーザーのコマンドを受け付ける一番小さなスケール(エディット・ウィンドウ)を最上層に、その影響が一定範囲に及ぶと、より大きなスケールを扱う第二階層に影響が及び、さらにまとまると第三、第四と大きなスケールの階層へと影響が積み重ねられていきます。ここで各層で処理されるグリッドの範囲は、上層ほど細かく、下層になるほど広い範囲を覆うようになっています。
このような手法を「影響マップ」(Influence Map)と言いますが、シムシティでは影響マップを多層的に積み上げた方法が取られています。つまり、各スケールの階層内での水平的な影響の伝播と、上下の階層間での異なるスケール範囲での影響の伝播という、2つの方向で影響が双方向的に伝わっていきます。
空間的な影響範囲の大小だけでなく、それぞれの階層の影響は時間単位も異なっており、上層の小さなスケールの影響は素早く、下層の大きなスケールになるほど、ゆっくりと影響が波及します。そのようなユーザーのコマンドを起点とする小さく細かい影響が徐々に大きく重なりながら上層から下層に伝わり、一方では逆に下層から上層へも各層の影響シミュレーションの結果が加算されながら伝播してくるので、最上層ではこのような全層でのシミュレーションの時間分を経てから影響が現れます。
このような手順で、『シムシティ』の街の自動生成は行われています。
参考: ウィル・ライト著、多摩豊訳『ウィル・ライトが明かすシムシティーのすべて(コンプコレクション)』角川書店、1990年、pp.46-49
デジタルゲームのフィールドとキャラクターを媒介する「ナビゲーションAI」
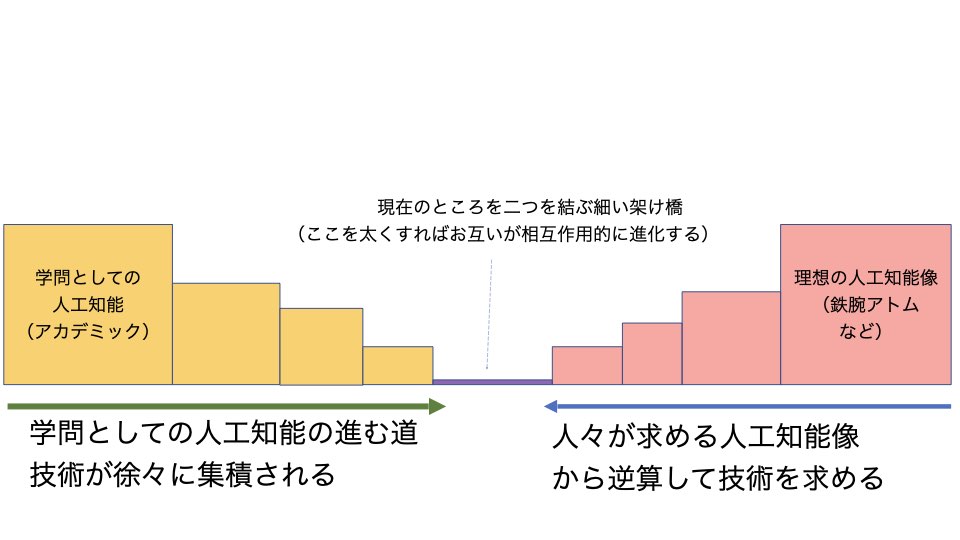
以上のようにデジタルゲームで描画され、自律的に発展するフィールドは、ボードゲームのように平坦ではありません。山や湖といった多様な地形があり、物や岩や植物(オブジェクト)があります。そのようなさまざまな場所にある地形を利用して行動するためには、どのような地形でも認識して行動に活用できる、より汎用的な人工知能が必要です。しかし、このような汎用的な知能の実現は現時点ではとても難しいものです。こういう時、人工知能では、より小さな人工知能に分けて協調させることで実現する、というアプローチがあります。これを「分散協調人工知能」と言います。
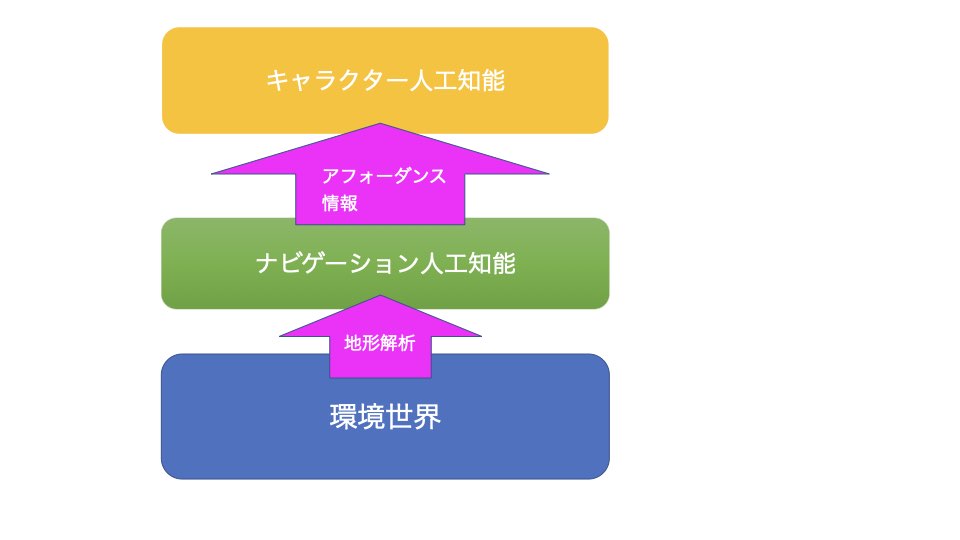
この場合は、意思決定を行うキャラクターAIと、地形の認識を担当するナビゲーションAIに分割します。ナビゲーションAIが担当するのは、
(1)どこを歩いて良いか(ナビゲーション・メッシュ)
(2)どのオブジェクトにどのような行動を取ることができるか(アフォーダンス)
という処理です。広い意味では、(1)もアフォーダンス情報に入りますので、ナビゲーション人工知能は端的に言えば、環境世界のアフォーダンスを抽出し、キャラクターに与える役割を持ちます。ナビゲーションAIは「環境とキャラクター人工知能を結ぶ」役割を果たしているのです。
オープンワールド時代に対応して複雑化した現代のゲームAI
現代のゲームは、オープンワールド型が主流になりつつあります。『Fallout』『Skyrim』(いずれもBethesda Game Studios)、「グランド・セフト・オート」(Rockstar Games)シリーズなど一千万本を超えるシリーズは、いずれもオープンワールド型ゲームです。オープンワールド型ゲームとは、広大なマップを持ち、シームレスに移動可能で、基本的にどの場所でも行けて、どのようなことをしても良いというゲームです。もちろん、ゲームによってミッションの順番やオープンになっていない場所があるなどの違いはありますが、ユーザーに最大限の自由度が与えられているゲームのことを言います。
感覚としては『バンゲリングベイ』(ハドソン、1985年)と似ているかもしれません。『バンゲリングベイ』は後に「シムズ」「シムシティ」シリーズを大ヒットさせることになるウィル・ライトが作ったゲームで、本人の談によるとオイルの色が川の色と同じで透明色になってしまったので、よくわからないゲームになってしまった、とのことです。私もマップの隅々をヘリコプターで飛び回っては敵基地のようなものを破壊していましたが、何のために何をやっているのか最後までわかりませんでした。しかし、あのどこに行ってもいい、何をしてもいい、というゲームの中で放り出された気持ちは現代のオープンワールドゲームと似ているかもしれません。
ゲームが広大になると、そこで活躍するための人工知能は、一定の場所でのみ活動する制約された人工知能と違い、いたるところで知的な活動を求められます。一緒に旅する仲間など、広大なマップに適応する人工知能はより汎用的な人工知能である必要があります。その知的構造はとても大きく深いものになります。たとえば、『ディビジョン』(Ubisoft, 2016)のキャラクターAIの内部構造は巨大なものになっています。
それぞれのキャラクターが持ち場を持ち、その中でキャラクターを動かそうとするときには、問題を限定することができます。逆に、切り分けた問題ごとにキャラクターを割り当てるとも言うことができます。人工知能が解くべき領域のことをフレームと言います。フレームの中で設定が多くなるほど、そしてフレームが広くなるほど、人工知能が抱える問題は重たく深くなります。それはそのままコンピュータの負荷に直結します。オープンワールドのゲームでは人工知能が持つフレームをどんどんと人間が広げてあげる必要があります。
しかし、フレームを広げていけば、それを抱える人工知能の内部構造もまた必要となります。すると、その内部構造自体が、それ自身の制限を持ち始めます。つまり、フレームを単純に無限に広げていくことはできません。知能の内部の統一性を保ったまま広げるためには、段階的な組み換えが必要とされます。それはちょうど我々人間が子供から思春期を経て大人になる苦悩と似ています。その道のりは決して線形でも平坦でもありません。
同じように、人工知能は最初に獲得した知能の形をある程度保持しつつ賢くする必要がありますが、それはとても難しい過程です。プログラマがプログラムを書いて拡張する時でさえ、元のプログラムとの整合性を気にしながら書かねばなりませんし、それが不可能な場合には全面的に書き直すことすら珍しくありません。つまり人工知能は構造的な進化を経て、より高度な存在になっていきますが、それは根本的な改革であるがゆえに、単なる適応型学習では実現することはできません。
ゲームキャラクターの人工知能はゲームのオープンワールド化に伴い、直面する世界が深く広くなる「フレームの拡大」に直面してきました。ゲームが当初の仕様を超えてどんどんと拡張して作られていくのが普通ですので、最初の仕様は基礎にはなっても、すべてではありません。そこで、ゲームAI技術は柔軟に自身を変えていける仕組みを自らの内に持つ必要があります。

ゲームAIに求められる三つの方向性
その仕組みに必要な性質が、「拡張性」「多様性」「カスタマイズ性」の三つです。この三つを兼ね備えることで、さまざまなキャラクターの人工知能を統一されたシステムの中で構築することが可能になります。同時にそれは人工知能の汎化(汎用性)を高めることになります。つまり、ゲームの開発スタート時にそのゲームで要求される人工知能の構造を決定し、その構造の中で、この三つの性質を持つように設計しておくのです。
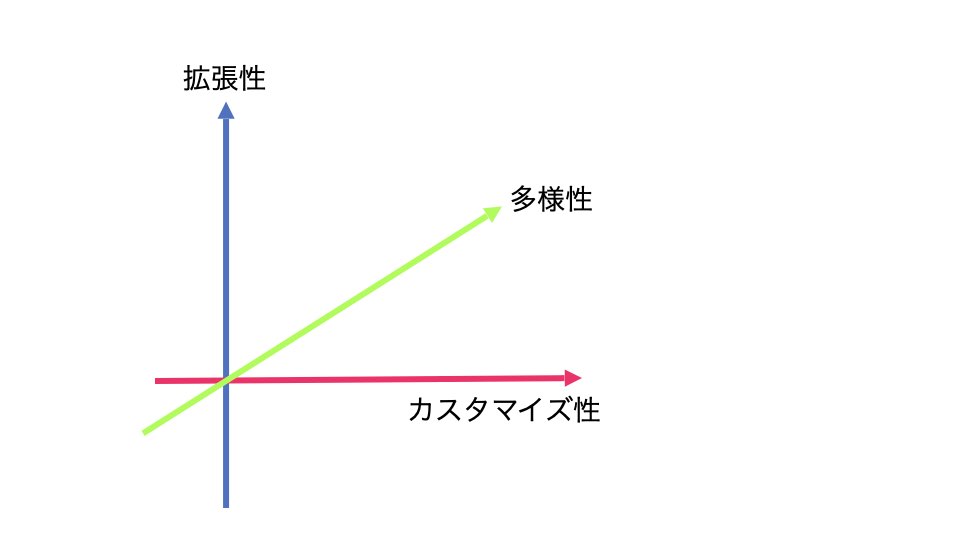
その一方で、現在の実用的な人工知能技術の基盤になっているニューラルネットワークは、柔軟な学習手法ではありますが、必ずしも拡張性に優れているとは言えません。一度学習してしまうと、次の学習は前の学習を上書きしてしまいますので、そうしないためには、もう一度全体を学習し直す必要があるからです。つまり拡張性はありますが工夫の必要があり、カスタマイズ性がとても低いのです。
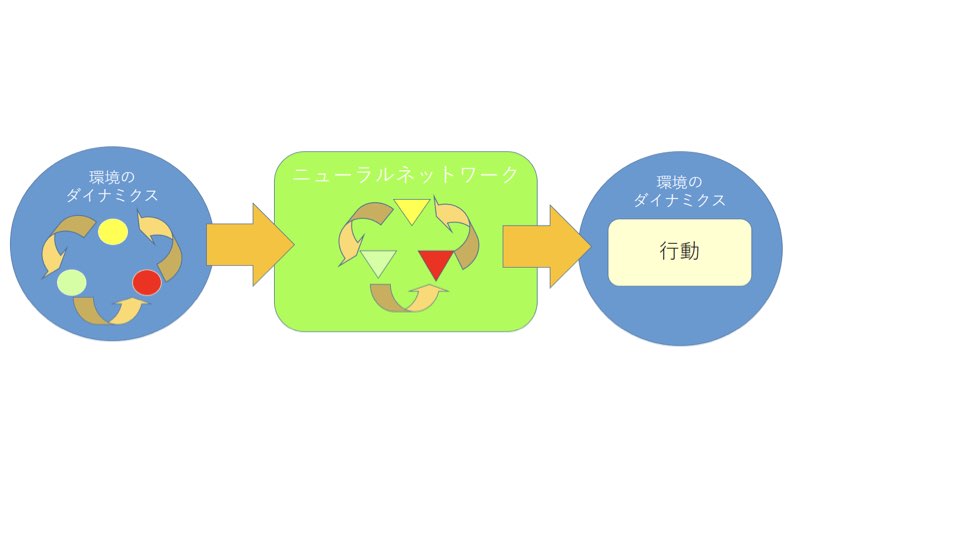
逆にニューラルネットワークの長所は、自律型の学習機能にあります。環境の情報をリアルタイムに取得し続けるパーセプトロン型のニューラルネットワークは、ディープラーニングの場合は特に、自分の内部に世界のダイナミクスを写すことができ、そのダイナミクスから出力を生成することができます。その際には、何が正解かを人間が指定する場合を教師あり学習、環境からの反応によって学習する場合を強化学習と言います。
人工知能が直面する世界が広く、深くなるほど、人工知能もまたその内面を広く、深くする必要があります。世界の複雑さそのままではないにしろ、それに対応する内面を持つ必要があります。
ゲームキャラクターがゲームの中で理解する必要があるのは、環境(空間、時間変化)とストーリーです。世界を深く理解するほど、そのキャラクターはその世界に深く存在することになります。従来の「世界のギミックの一部となる」、つまり物理的に埋め込まれているだけでなく、キャラクターは自律性をもった精神的(知能的)存在として、自ら「その世界に属する」ことが必要となります。世界にきっちりと根を張る必要があります。
しかし、世界がより広く、深く、ストーリーが巨大なものになればなるほど、キャラクターの知能はより大きく深いものと直面することになります。それを考えることは、ゲームに限らずこれからの人工知能の未来を考える上で、とても重要なことです。
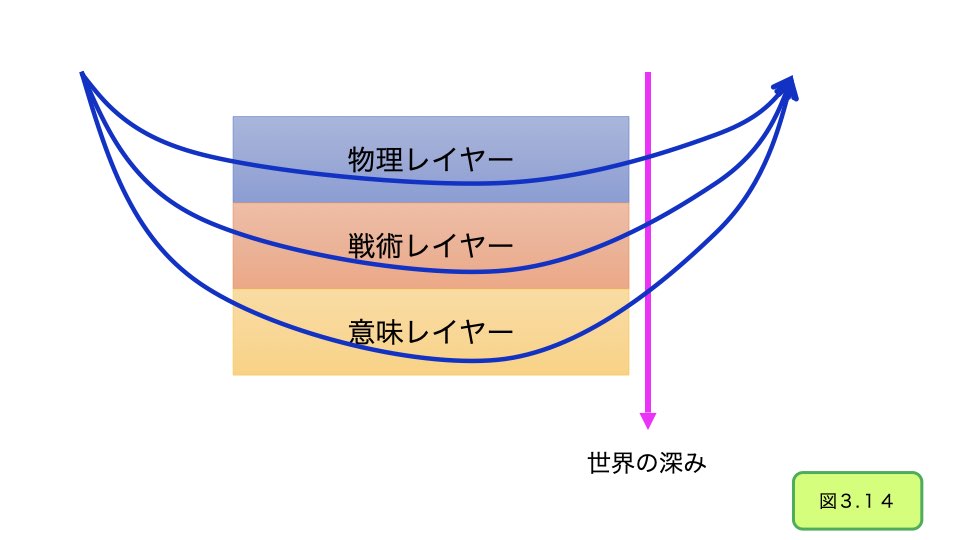
世界の中にある人工知能という視点から眺めてみましょう。世界から突きつけられるものは、まず物理的な現象です。ボールが飛んできたり、剣が振り下ろされたり、そういった物理的な事象に対応する知能というものがあります。これを物理レイヤーと呼びます。
次に、より長い時間の状況の変化があります。物理的な対応をしていただけではわからない、戦術的な状況の変化です。味方の基地を防衛したり、敵の城を攻めたりという現象の次元です。これを戦術レイヤーと呼びます。
さらに、より大きなミッションや使命というものがあります。ゲームの中で果たす役割、というものです。それはとても抽象的なもので哲学的なものです。たとえて言うならそれは、我々人間が「この世界で生きる意味」を求めるのと似ています。これを意味レイヤーと呼びます。
このように、物理レイヤーから意味レイヤーまで、ゲーム世界に直面するキャラクターはさまざまなレベルで世界に参加します。このレベルが深ければ深いほど、高度な人工知能が求められます。
キャラクターがより深く世界と関わっていくとき、人工知能に求められるものは何か? そのときのキャラクターの知能の構造は、どのように深化する必要があるのか? それこそがデジタルゲームにおける人工知能の最も重要なテーマの一つです。
キャラクターAIに認識や感情を持たせるには
以上のように、ゲームAIの場合には、きわめて具体的な世界の状況に対してキャラクターの知能を形成していきます。そして、高度なキャラクターの場合には、何重にもフレームを重ねることで、より複雑な意識を形成することになります。
では、キャラクターAIに感情や不安や希望といった精神活動をどのように実装できるのでしょうか。現行の技術の延長線上で考える場合、それは世界の見え方の中に定義することで実現します。
たとえばキャラクターAIには、敵キャラクターに対しての「脅威度」というパラメータを持たせることができます。これは敵キャラクターが持つ体力や魔法力などと言った客観的な指標ではなく、今、その状況下で、敵キャラクターがどれぐらい自分なり守るべきキャラクターに対して大きな危害を加えそうか、と言った予測値となります。この脅威度によって最初に攻撃する敵キャラクターを決定します。また、土地に対する感覚があります。先の例では自分の陣地に「守るべき土地」というラベルを付けます。このようなラベルのことをゲームAIでは「タグ」と言います。
街の大通りには「騒がしい」「楽しそう」というタグを付けますし、薄暗い広場には「さびしい」「危険」というタグを付け、深い森の中の道には「暗い」「見通しがよくない」などのタグを付けます。このようなタグはキャラクターAIの行動を形成するときに利用されます。このように世界の見え方を定義することで、キャラクターAIの意識や精神の状態を規定していきます。たとえば、仲間が同じ街にたどり着いて散歩するとしたら、より「楽しそう」なタグがついた場所をめぐる、という行動を取らせることができます。
もちろん、本来の精神や意識は、このような人間が外から与えるタグではなく、環境と内面の相互作用によって自律的に形成されるのが理想的です。しかし、そのような自律的、かつ自発的な精神の活動を、人工知能はいまだ獲得していません。そのような活動は、身体なくしてはあり得ないものでしょう。
たとえば、ある場所に入ったときの明るさ、香り、湿気、空気(風)から、人はその場所に対する印象を形成します。そして、そこから自分自身の身体や精神に及ぼす影響を予測し印象を決めます。キャラクターAIで言えば、自らタグを形成します。そのような自律的ダイナミクスを持つ人工知能を作っていくことが、これからの課題になるでしょう。
ただし、それぞれの人工知能がそのようなダイナミクスを持って自律的な活動を獲得すればするほど、逆に言えば扱いづらくなります。自律性と可制御性はトレードオフの関係にあります。フレームが完全に想定される問題に対しては、自律性の弱い可制御性の強い人工知能に対応させるのが良いでしょう。現在のほとんどの人工知能はこの形になっています。
しかし、フレームの内容が高度で複雑な場合には、自律性が強くて可制御性の弱い人工知能の方が適しています。そして、その場合に、どのような身体の、そして精神の自律的なダイナミクスを持たせれば良いかという問題は、まだ十分に研究されていません。
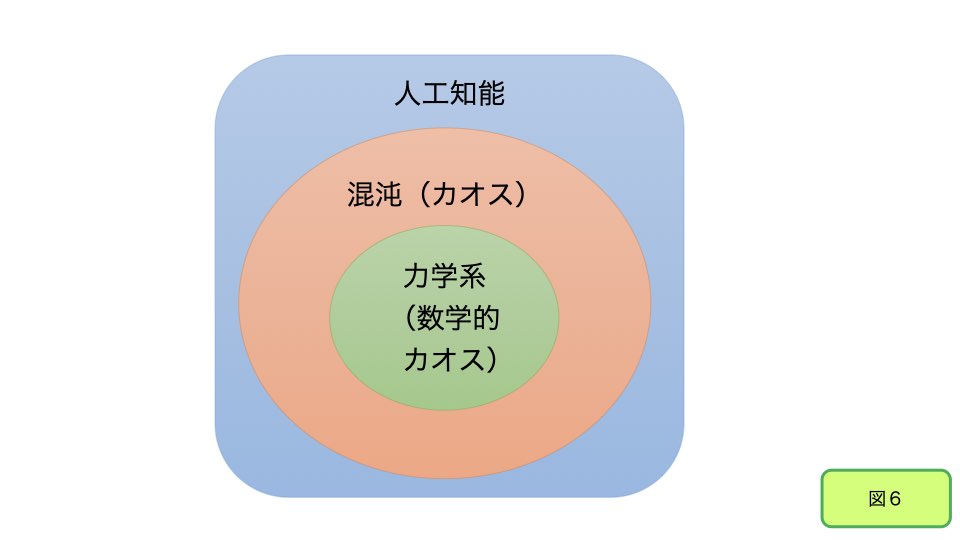
人工知能のカオス存在理論
環境を巻き込み、巻き込みつつ行動を生成するダイナミクスこそは、人工知能の特徴そのものです。身体レベルでは、このダイナミクスを散逸構造と言います。エネルギーを得つつ、消費し、エネルギーを出すことで、生物は身体の動的平衡状態をかろうじて保っているのです。人間の知的活動も同様の散逸構造を持つ運動であり、カオスや熱力学や統計力学、刺激や情報の流れと自然な関連を持ちます。人工知能も同様であり、これらの技術との深い関連の中で、再構築されようとしています。
これは大きく見れば、単純な機能を相互に連関させていくことで混沌を獲得する「自律型カオス力学系」と呼ばれる手法の一つに分類できます。
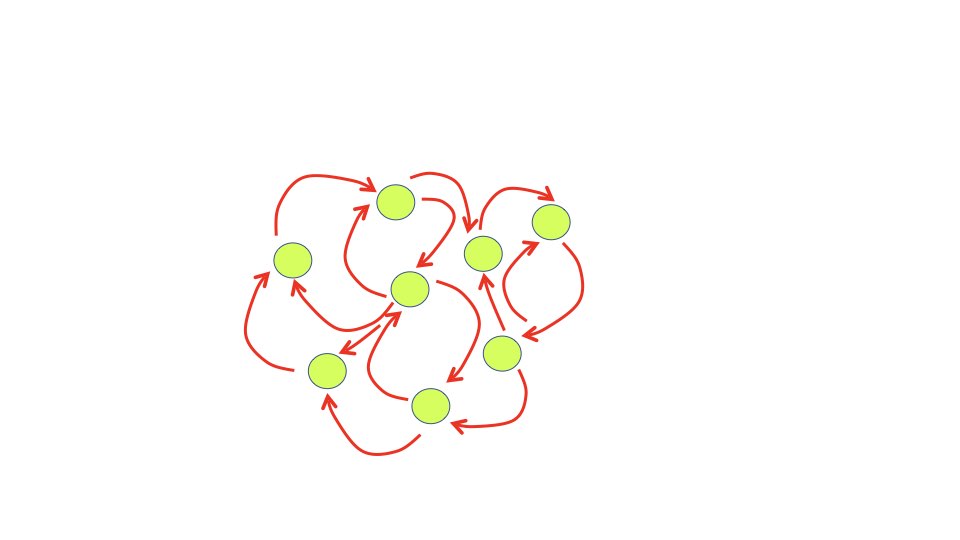
力学系とは「絡み合う複数の要素が時間と共に変化するシステム」のことです。特にこの力学系が「繰り返す動的な運動をボトムアップに持つ」場合には「自律型力学系」、さらに、外界からのインプットに関してセンシティブ(鋭敏)に運動を変化する場合に「自律型カオス力学系」と言います。イメージとしては、天井から吊り下げられたたくさんの振り子がお互い細い糸でつながれている場を想像しましょう。いくつかの振り子を力強く動かすと、力が伝搬して全体として複雑な振り子運動が生成されます。振り子は現実の物理空間の中にありますが、「自律型カオス力学系」の法則性を数学的に解析するためには、より抽象化された物理量で構成される位相空間を用いて記述する必要があります。これが、自然界に存在する一般の力学系のモデルです。
これと同様、私自身も知能を「外部環境と内部構造の相互作用による情報の混沌の中から自律生成されるカオス力学系」とみなして人工知能を構築するという試みに長い間関わってきました(これは私の博士課程の頃からのテーマでありました)。現在も続けていますし、またこれからもこの手法が最も有望であると感じています。
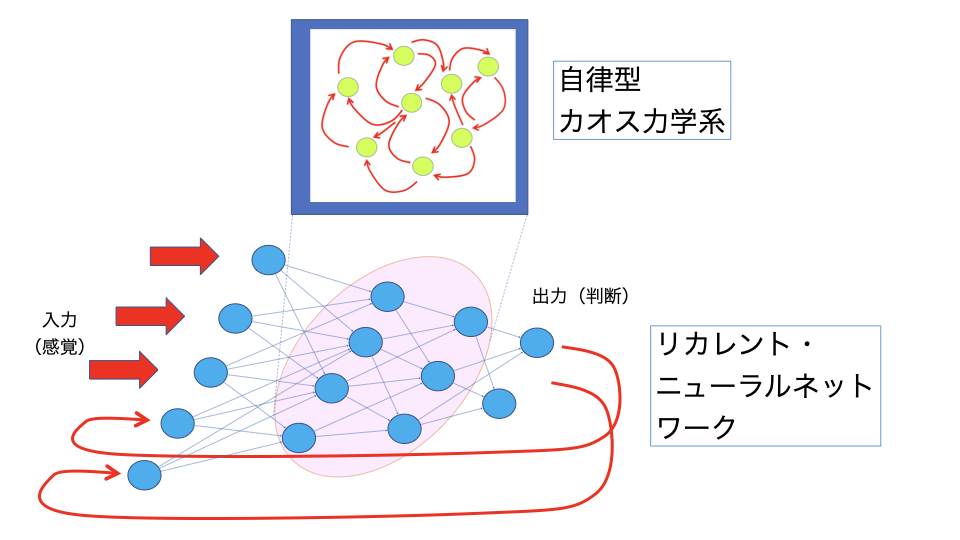
混沌からの人工知能を生成するもう一つのアプローチとしては、「リカレント・ニューラルネットワーク」を用いることが考えられます。
ニューラルネットワークとは脳の神経回路を模した「電気回路シミュレータ」です。通常、ニューラルネットワークは多層構造を持っており(パーセプトロン型)、入力(感覚)から出力(判断)に向かって信号が進んでいきますが、リカレント・ニューラルネットワークでは、出力を入力にもう一度戻します。こうすることで出力と入力が混じり合い、感覚と判断が、あるいは客観と主観が混じり合うのです。
こうしてリカレント・ニューラルネットワークを動かしていると、次第に、このリカレント・ニューラルネットワークを構成する要素の間に「自律型カオス力学系」が出現します。正確には、その場合、ニューラルネットワークは少し複雑な構造を持つ必要がありますが、本質的には自己ループバック構造と世界とのインタラクションの中からカオスが生まれます。
ただし、こうしたアプローチは人工知能研究の中に閉じているかぎり、とても数学的でトリッキーなものに見えてしまいます。このアプローチにしっかりとした基盤を与えようとするならば、まず哲学の領域から土台を築く必要があります。それもより深い基盤として、東洋哲学的な思想の上に構築することが自然です。
というのも「混沌からすべてが生まれる」という思想は、東洋哲学においてこそ根源的なものであるからです。知能を作るという試みの中では、東洋と西洋の二つの知見がおのずと必要になります。人工知能を作ろうとする行為は、まさにこの二つの世界の潮流を結び合わせる役目を持っているのです。
それは我々の見方を逆転させることでもあります。混沌を人為的に構成する、という見方ではなく、まず知能とは混沌であり、その表現として「自律型カオス力学系」があるという見方です。ですから知能の根底である混沌を知ることこそが、知能を形成するための最大のヒントであり、それを「自律型カオス力学系」の力を借りて描き出す、ということでもあります。