さて、早速ではありますが、国内最大級のゲームカンファレンスであるCEDECが、今年も8/23〜25日の3日間、パシフィコ横浜ノースおよびオンラインにて開催されています。
様々な分野のおよそ200ものセッションが開かれる中から、今回は、AIを用いてゲームシナリオの文章や音声からキャラクターの感情を分析し、その場面に応じた適切な表情を自動で求めるツールの開発に関する、『AIによる自然言語処理・音声解析を用いたゲーム内会話パートの感情分析への取り組み』という興味深いタイトルのセッションについて、その内容をまとめていきたいと思います。

文/DuckHead
「シナリオテキスト」と「収録ボイス」に込められた感情をAIが分析し、「キャラの表情」を決定する
本講演にて登壇されたのは、株式会社Cygamesにて開発運営支援を行い、2019年後半からはAIの社内導入に取り組んでいる立福 寛氏。
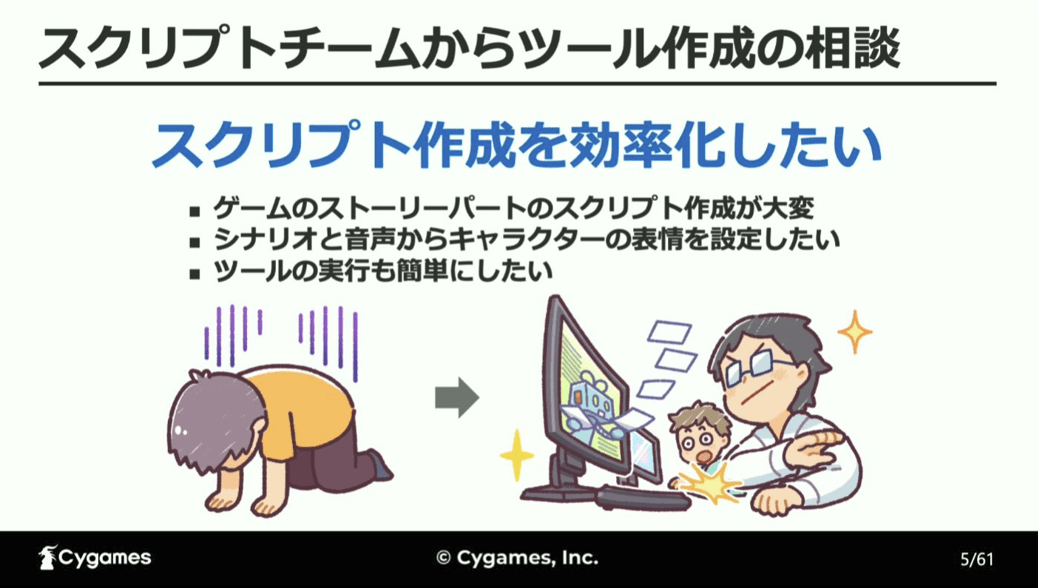
立福氏がAIを用いた感情分析に着手したのは、ゲームの簡易プログラムであるスクリプトを作成するチームから、シナリオと音声から表情を自動で設定し、ストーリーパートのスクリプト作成作業を効率化できないかという依頼があったため。
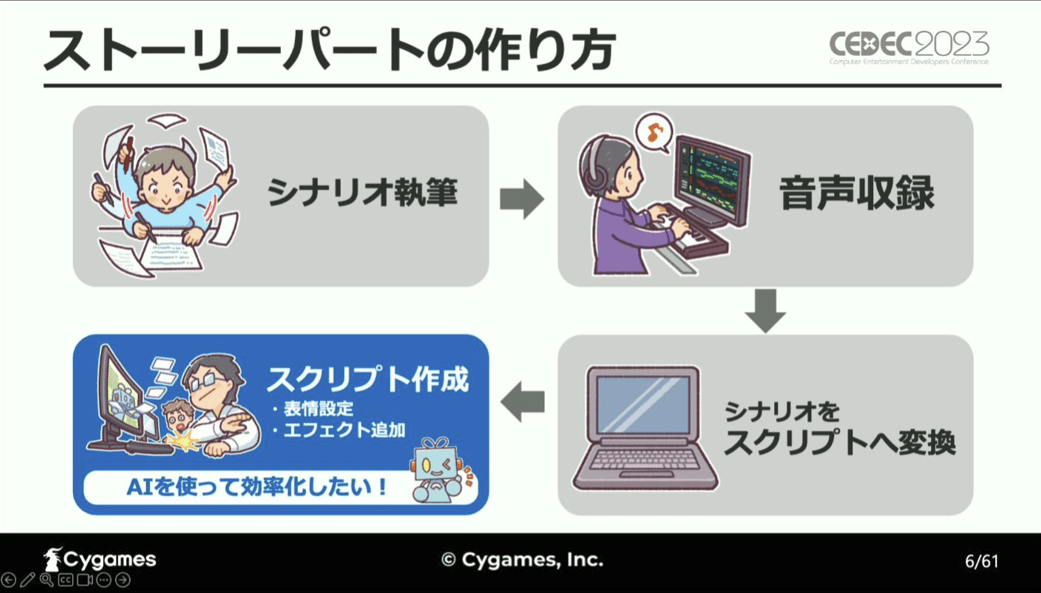
ゲームのストーリーパートは、
①シナリオ執筆
②シナリオの台詞部分を抜き取り、音声収録
③シナリオをスクリプトへ変換
④スクリプト作成
という流れで進められており、AIを用いて表情を自動で求めるツールによる効率化を狙うのは、④のスクリプト作成です。

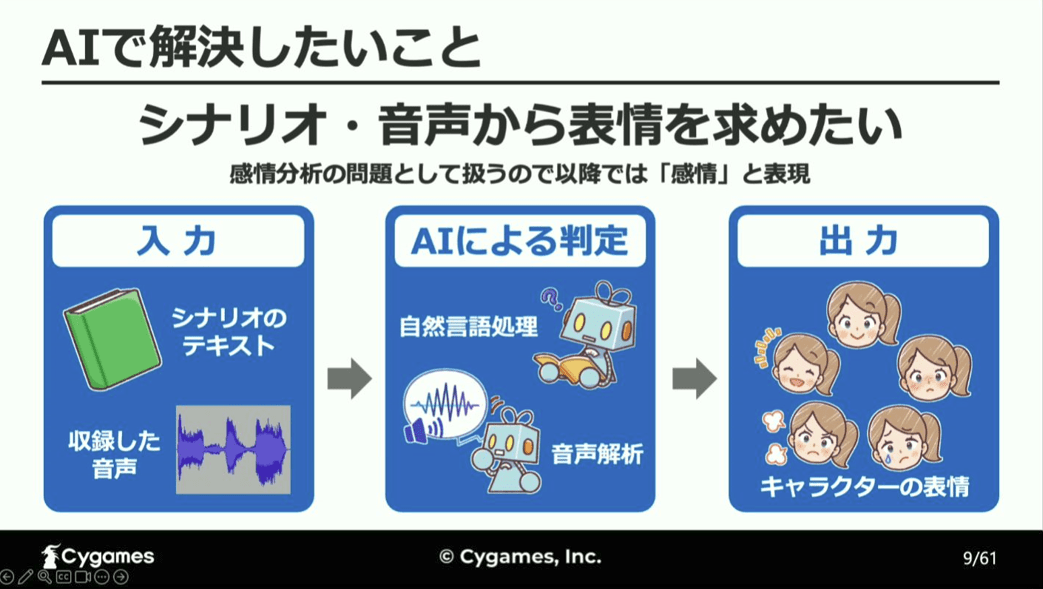
ストーリーパートにおけるスクリプトとは、キャラクターやセリフ、背景などを指定してストーリーパートを制御するためのものであり、今回開発するのは、入力されたテキストや音声をAIで判定し、その場面に会った適切な表情を指定するツールとなります。
なお、このツール開発は感情分析分野に関わるものであるため、以降、感情と表情は同じ意味の言葉として扱います。

今回、AIによって感情を設定する対象となるシナリオは、1行の会話文。
これらの文章は1文の中に複数の感情が設定されており、文章が短すぎる場合などを除いて、句読点と記号で感情が区切られ、全ての部分に何かしらの感情が割り振られていています。

そして、AIによって分析および設定する感情は、「標準」、「喜び」、「悲しみ」、「怒り」、「照れ」の5種類。実際には、これらの「基本感情」に該当しない感情のバリエーションがあるのですが、それらは「標準」として扱うとしています。
更に、今回は5種類の感情をより大雑把にまとめた、「標準」、「ポジティブ」、「ネガティブ」の3種類に分類するパターンについても検証を進めています。

また、今回取り扱うシナリオは、1人のシーンか複数人の会話シーンであり、キャラクターの音声が必ずあるわけではなく、ない場合も存在します。

以上の条件で、今回検証を行ったAIを用いた感情分析は、「自然言語処理による感情分析」と「音声解析による感情分析」の2種類。
ここからは、手法ごとにこれらの分析結果について詳しく見ていきます。
自然言語処理による感情分析

まず最初に行ったのが、「自然言語処理による感情分析」の検証です。
この自然言語処理による感情分析にもいくつかの手法があり、手始めに、感情を属性としてテキストの部分ごとに割り当てて学習データを作成するという、固有表現抽出タスクによる感情分析に取り組んだと言います。

その結果は、「分析精度が非常に低い上に、属性を割り当てる範囲がほぼ一致せず、文章の一部にしか属性が割り当てられなかった」と報告しており、推論時に属性を求める範囲が不明であったことがその原因と考察し、今回の用途に固有表現抽出タスクは向いていなかったと結論付けています。

この結果から、「そもそも自動言語処理によってどの程度感情分析をすることができるのか」という疑問が生じ、自動言語処理の1番の基本となる文章分類タスクを用いた検証を1行単位と句読点単位で進めたと、立福氏は言います。

まずは、1行単位の文章分類の検証について。
この検証の問題点として、1行に複数の感情が入っていることが挙げられ、「標準」が登場する頻度が非常に高いことから、感情を標準をベースとする5種類の分類パターンと3種類の分類パターンに分けて検証を進めたとしています。

また、本検証データの精度を上げるために、複数の方法で文章の水増しを行った結果、どの手法でも精度をあげることはできなかったと報告しています。
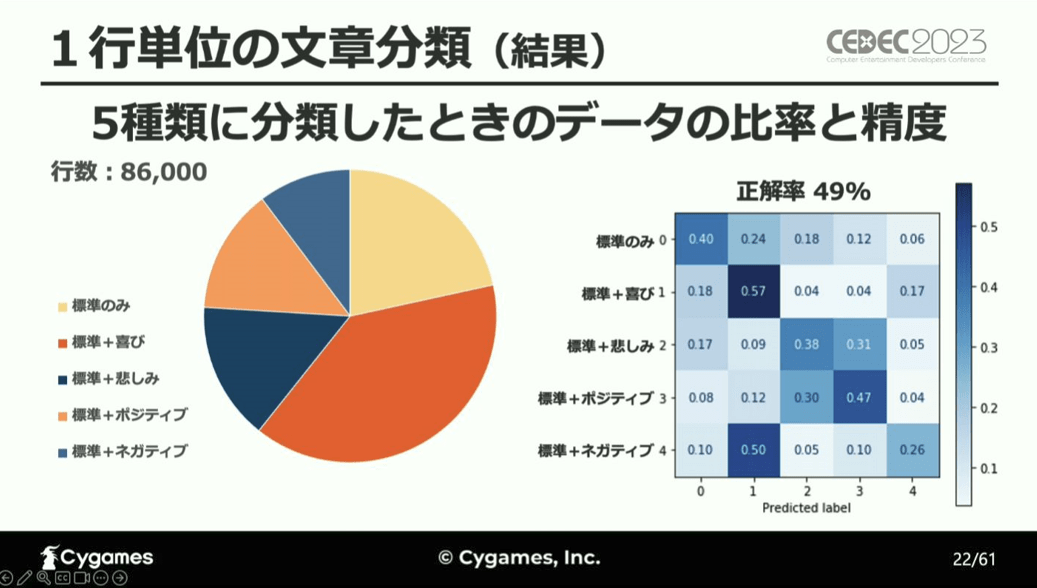
こちらが、感情を5種類に分類したときの検証結果で、右図の左上から右下の対角線が各感情に対する正解率を表し、正解率が高くなるほど色が濃くなっています。
立福氏はこの結果を受け、「5種類に分類した場合の正解率は49%で、あまり高くなかった」としています。
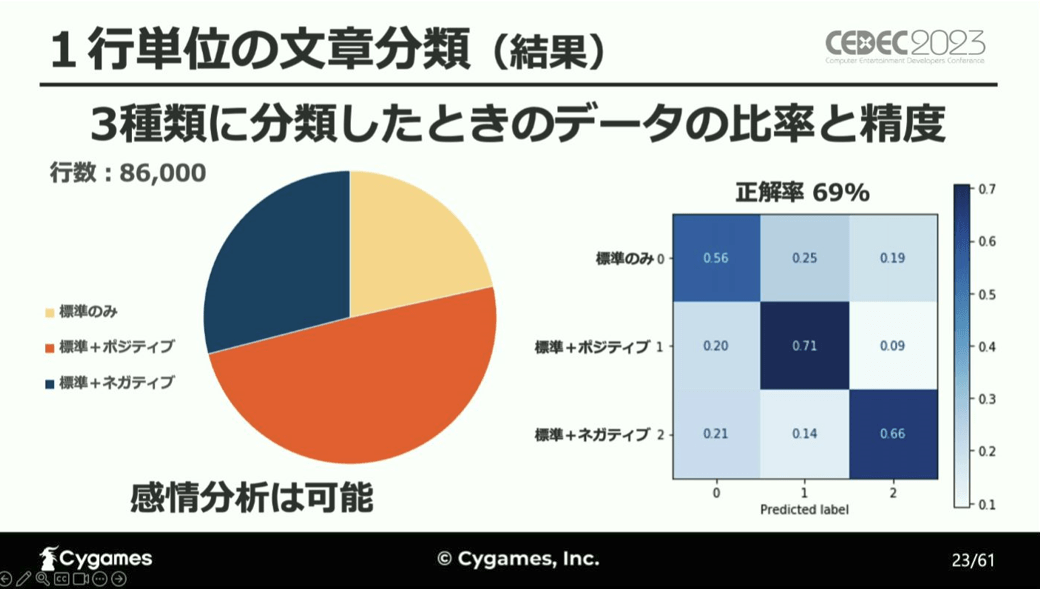
続いてが、感情を3種類に分類したときの検証結果。
「正解率が70%にまで上がり、この精度であればツールとして使用可能だ」と立福氏は言い、文章分類による感情分析は可能だと結論付けています。

次に、実際のスクリプト作成作業で用いられる句読点単位での感情分析の検証となります。
句読点単位の分析では、1行単位の時よりも分析精度が下がっているという結果となり、句読点単位では文字数が少なく得られる情報量が少ないこと、前後の文章の情報が分からないこと、人間でも感情の判断が難しい文章があることが原因と考えられ、別のアプローチをする必要があると結論しています。

以上のことから、AIを用いて感情分析をする際には、感情を求めたい文章と、その前後の文章、これら2つの情報を渡す必要があると結論することができ、これは質問応答タスクの応用により実現可能とし、検証に進みます。


質問応答タスクとは、コンテキストと質問から回答を返すタスク。
今回の場合は、コンテキストは感情を求めたい文章とその前後の文章で、質問が感情を求めたい文章となり、AIはその質問への回答として感情に割り当てられた数値を返します。

また、質問応答タスクには、コンテキストから回答を抽出する「抽出型」と回答文を新規生成する「生成型」があり、今回は精度が高くなる「抽出型」を用い、コンテキストの先頭に数字を追加することで、AIがその数字を抽出して返すという手法を作成しています。

これらのコンテキストに可能な限り前後の行の文章を追加した状態で作成したデータで学習とテストを行った結果、これまでの検証で1番高い感情分析精度を記録したと報告しています。

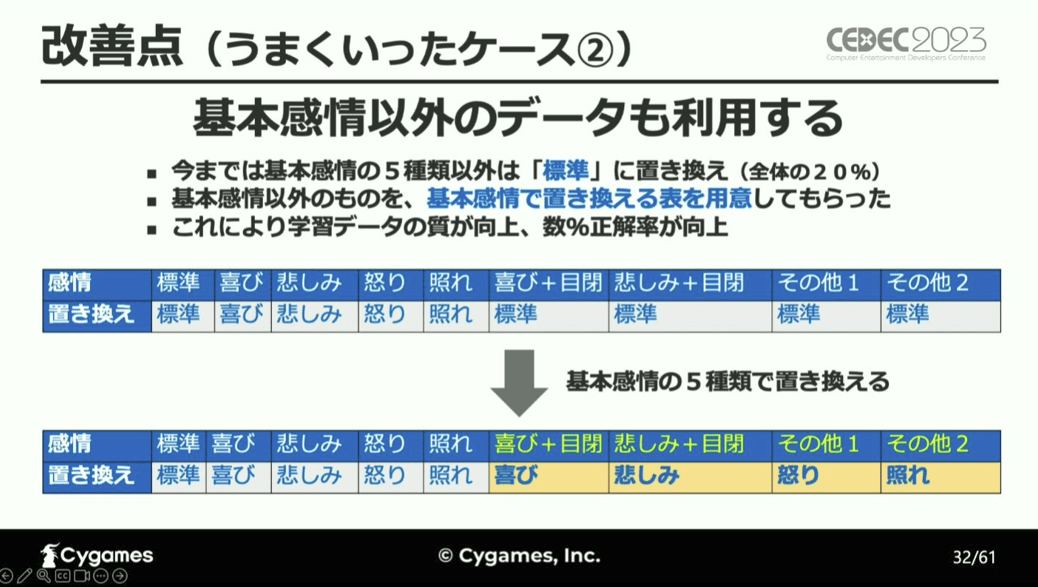
この結果を改善するためにいくつかの方策を試したところ、バッチサイズの増大やBERT系のモデルを適切に設定することで更に精度が上がったとし、更に、学習データの見直しとして、これまで5種類の基本感情以外の感情を「標準」としていたところを、キャラクターごとに基本感情に置き換え直した結果、よりAIが学習しやすくなり正解率が数%向上したと言います。

逆に、文章の水増しによる学習データの水増しや、モデルのトークン数を増やしてAIに与える前後の文章をより長くした場合については、分析精度が上がらなかったと報告しています。
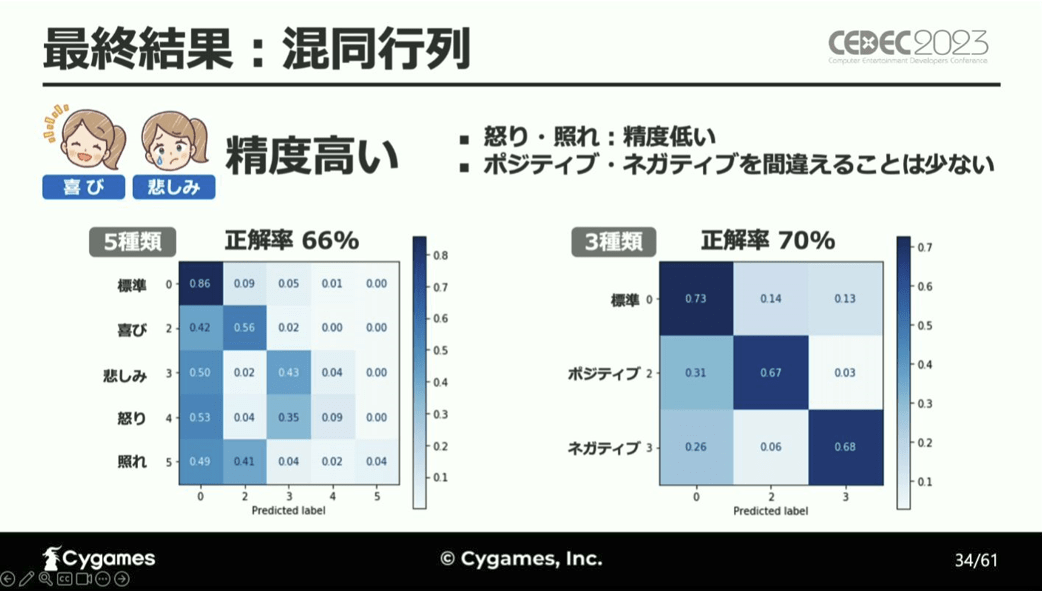
各改善点を検討し、最良の条件を整えた後に感情分析をしたところ、全体の正解率は、5種類に分類した場合は66%、3種類の場合は70%と精度が高く、ポジティブとネガティブの区別を間違えることは少ないという結果になった一方で、「怒り」と「照れ」の正解率が非常に低かったと、立福氏は言います。

そして、「怒り」と「照れ」の正解率が低い原因については、「怒り」と「照れ」はそもそものデータ数が少なく学習が他のデータほど十分ではなかったことや、「怒り」と「照れ」は人間でも感情の判断が難しい文章が多かったためであると考察しています。
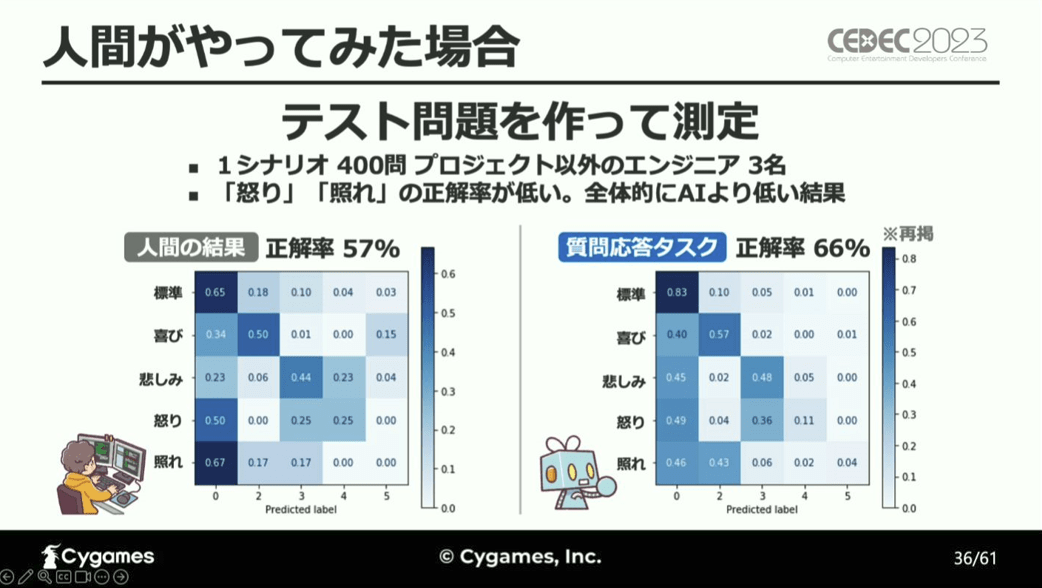
そこで、3名のエンジニアを対象にAIと同様のテストを使用し、その正解率を検証してみたところ、AIと同様「怒り」と「照れ」の正解率が低く、その他の感情についても全体的にAIよりも正解率が低かったと報告しています。
音声解析による感情分析

続いては、音声解析による感情分析について。
「音声の感情分析」は、「音声の分類」と捉えることができるため、まずは、音声から特徴を数値化し、CNNによって分類するモデルから検証を進めています。
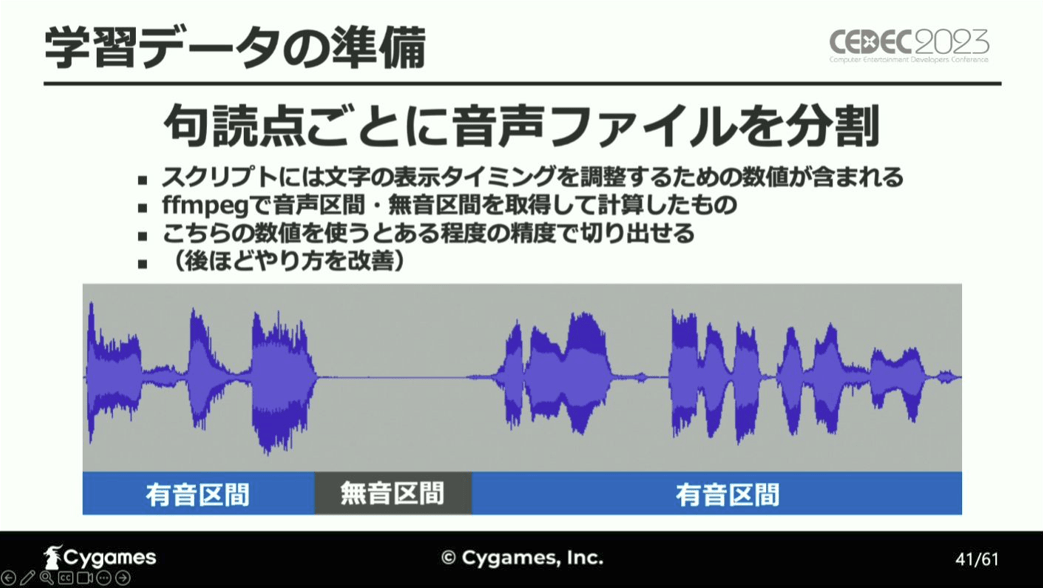
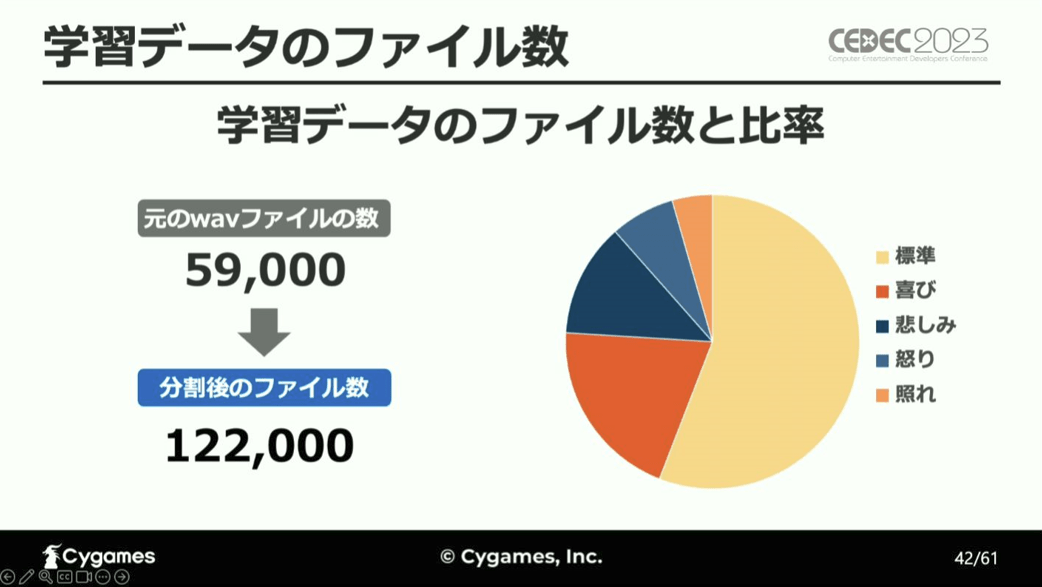
ゲームで使用する音声ファイルは1行ごとに分けられているため、これを句読点ごとに分割して学習データとし、感情分析を実行しています。

その結果、感情分析の正解率はおよそ30%と低い値を示し、この効果音を分類するためのモデルが感情分析に向いていないことが明確となり、次いで新たなモデルについて検証を進めています。


そして、内部的にはWav2Vec2を利用している感情分析が可能な音声解析パッケージ「Speech Brain」に対し、CNNモデル検証に用いた音声データを使用したところ、分析精度が高かったと報告しています。


しかし、これらのCNN分類モデルに用いた学習データは、正しく句読点単位に分割されているかが分からないという問題点があったため、音声認識モデル「WhisperX」を用いた音声分割をすることで、より精度の高い学習データを作成しなおしたと報告しています。

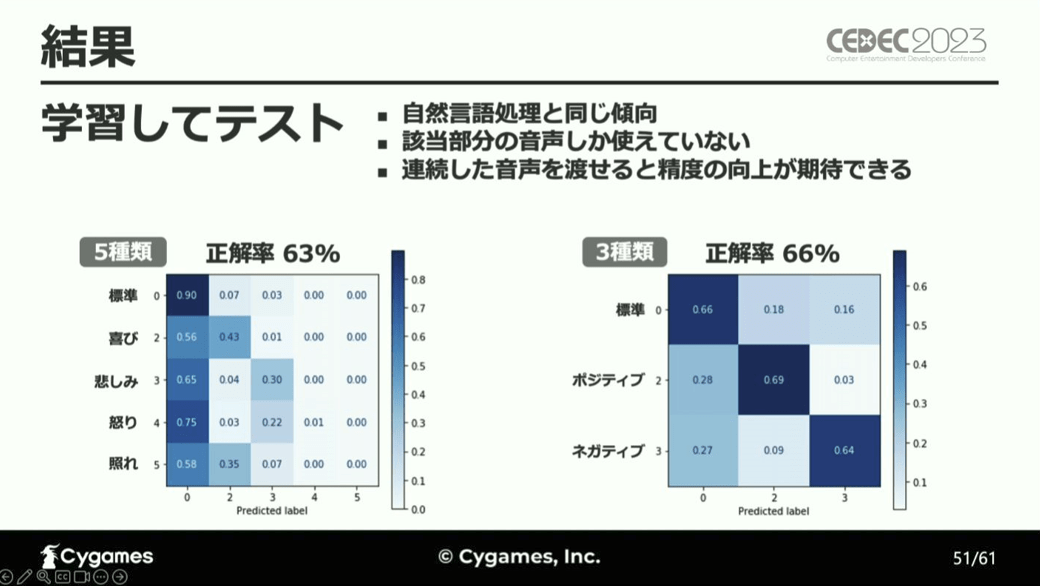
この学習データを用いて、音声解析による感情分析をテストしたところ、自然言語処理と似た傾向を示したものの、正解率は自然言語処理よりも低くなるという結果となり、その原因を、自然言語処理の場合と異なり、前後の文章の音声をAIに渡すことができていないためであるとし、この課題をクリアすることができれば分析精度の向上が期待できると考察しています。
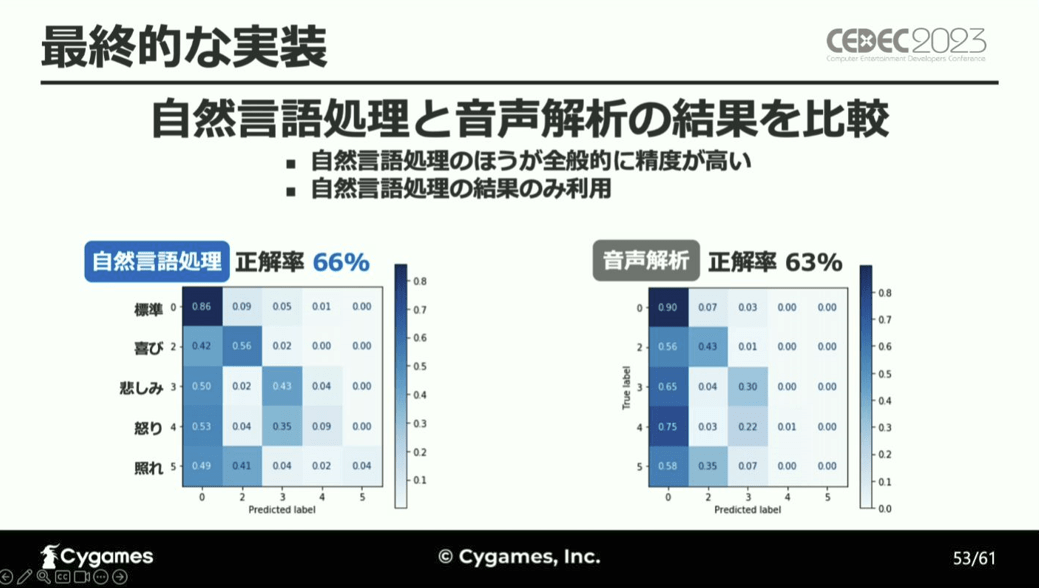
そして、自然言語処理と音声解析の結果を比較したところ、自然言語処理のほうが全体的に精度が高かったため、音声解析は不採用とし、AIによる感情分析の際に入力するのはテキストのみとすることに決定したと結論付けています。
感情分析ツールの提供
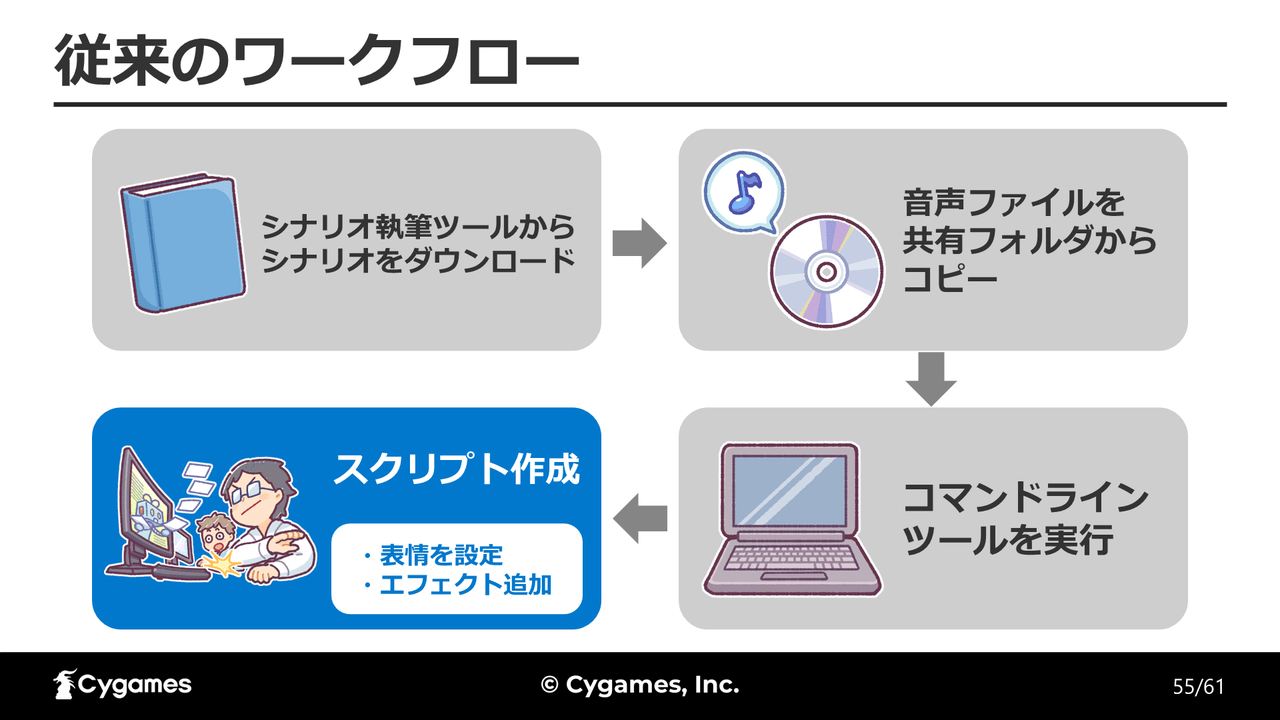

今回開発した感情分析ツールを導入した新たなワークフローは、ファイルのコピーなどといったスクリプト作成に必要な前準備を、自動化サーバー「Jenkins」によってまとめて提供し、その後にAIによる感情分析ツールを通して表情のスクリプトが設定されるというもの。AIの感情分析が正確ではないために修正の工程が必要なものの、手順は大幅に簡略化されたと立福氏は言います。


そして、AIによる感情分析ツールを導入したワークフローを構築した結果、スクリプトチーム全体で10%程度作業が効率化し、ツールの統合により、新規合流者がツールに慣れるまでの期間が大幅に改善したと報告しています。

今回の開発により、最終的な正解率が66%である、ポジティブとネガティブの間違いは少ない感情分析ツールが作成できたものの、「怒り」と「照れ」の推定の精度が低いという課題が見えたと報告しています。
また、今回は音声解析が自然言語処理の精度を超えられなかったという結果になりましたが、開発当時は音声による感情分析の既存事例が少なかったということもその理由の1つとして挙げられ、最近は感情分析事例も増えてきたため、しばらく時間をおいてから新たなモデルで検証したいと立福氏は言います。

近年、数多くの分野で導入されているAI。今後も様々な形でゲーム開発と関わっていくことと思いますが、その関係性がどのように変化していくのか、注目が集まります。